Detailed Workflow¶
This notebook walks you through a typical AutoEIS workflow, from data loading to visualization and model ranking. In summary, the steps covered in this notebook are:
Load EIS data
Preprocess EIS data (removing outliers, etc.)
Generate a pool of equivalent circuit models
Fit model parameters to the EIS data using Bayesian inference
Rank models based on goodness-of-fit and complexity
Visualize the results
Set up the environment¶
AutoEIS relies on EquivalentCircuits.jl package to perform the EIS analysis. The package is not written in Python, so we need to install it first. AutoEIS ships with julia_helpers module that helps to install and manage Julia dependencies with minimal user interaction. For convenience, installing Julia and the required packages is done automatically when you import autoeis for the first time. If you have Julia installed already (discoverable in system PATH), it’ll get detected and
used, otherwise, it’ll be installed automatically.
Note
If this is the first time you’re importing AutoEIS, executing the next cell will take a while, outputting a lot of logs. Re-run the cell to get rid of the logs.
[1]:
import ipywidgets as widgets
import matplotlib.pyplot as plt
import numpy as np
import numpyro
import seaborn as sns
from IPython.display import display
import autoeis as ae
ae.visualization.set_plot_style()
# Set this to True if you're running the notebook locally
interactive = True
Load EIS data¶
Once the environment is set up, we can load the EIS data. You can use ae.io.load_eis_data() to load EIS data from a variety of popular instrument formats (Gamry, BioLogic, ZPlot, Ivium, and more). See the Loading EIS Data notebook for details.
AutoEIS requires two arrays: Z and freq. Z is a complex impedance array, and freq is a frequency array. Both arrays must be 1D and have the same length. The impedance array must be in Ohms, and the frequency array must be in Hz.
For convenience, we provide a function load_test_dataset() in autoeis.io to load a test dataset. The function returns a tuple of freq and Z.
[2]:
freq, Z = ae.io.load_test_dataset()
Note
If your EIS data is stored as text, you can easily load them using numpy.loadtxt. See NumPy’s documentation for more details.
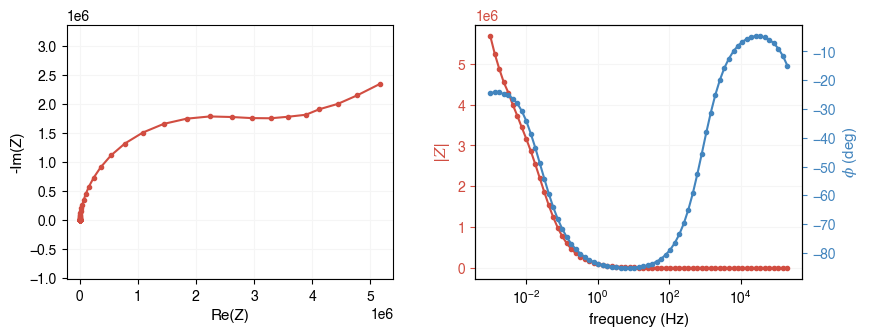
Now let’s plot the data using AutoEIS’s built-in plotting function plot_impedance_combo. The function takes the impedance array and the frequency array as inputs. It will plot the impedance spectrum in the Nyquist plot and the Bode plot. All plotting functions in AutoEIS can either be directly called or an Axes object can be passed in to specify the plotting location.
Alternatively, you can use separately call plot_nyquist and plot_bode functions to plot the Nyquist and Bode plots, in separate figures.
[3]:
ax = ae.visualization.plot_impedance_combo(freq, Z)
# Alternative way to plot the EIS data
# ax = ae.visualization.plot_nyquist(Z, fmt=".")
# ax.set_title("Nyquist plot")
# ax = ae.visualization.plot_bode(freq, Z)
# ax[0].figure.suptitle("Bode plot")
Note
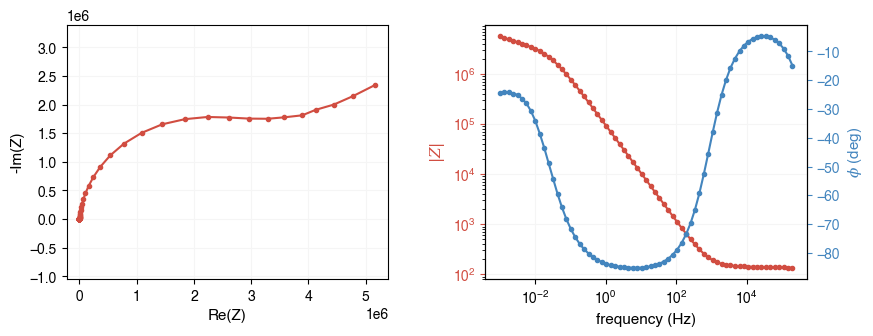
When plotting EIS data, much information can be lost if plotted on a linear scale (especially at high frequencies). It is recommended to plot the data on a logarithmic scale. You can do this by simply passing log=True to the plotting functions.
[4]:
ax = ae.visualization.plot_impedance_combo(freq, Z, log=True)
Preprocess impedance data¶
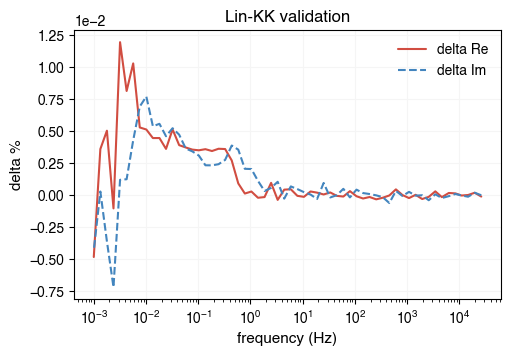
Before performing the EIS analysis, we need to preprocess the impedance data. The preprocessing step is to remove outliers. AutoEIS provides a function to perform the preprocessing. As part of the preprocessing, the impedance measurements with a positive imaginary part are removed, and the rest of the data are filtered using linear KK validation. The function returns the filtered impedance array and the frequency array.
[5]:
freq, Z, aux = ae.utils.preprocess_impedance_data(freq, Z, tol_linKK=5e-2, return_aux=True)
# NOTE: Since linKK could change `freq`, you should use `aux.freq` to plot the residuals
ae.visualization.plot_linKK_residuals(aux.freq, aux.res.real, aux.res.imag)
[18:59:18] WARNING 10% of data filtered out.
[5]:
<Axes: title={'center': 'Lin-KK validation'}, xlabel='frequency (Hz)', ylabel='delta %'>
Generate candidate equivalent circuits¶
In this stage, AutoEIS generates a list of candidate equivalent circuits using a customized genetic algorithm (done via the package EquivalentCircuits.jl). The function takes the filtered impedance array and the frequency array as inputs. It returns a list of candidate equivalent circuits. The function has a few optional arguments that can be used to control the number of candidate circuits and the circuit types. The default number of candidate circuits is 10, and the default circuit types
are resistors, capacitors, constant phase elements, and inductors. The function runs in parallel by default, but you can turn it off by setting parallel=false.
Note
Since running the genetic algorithm can be time-consuming, we have provided a pre-generated list of candidate circuits in this demo to get you started quickly. We’ve kept the flag as True for our integration tests to catch possible regressions. Set use_pregenerated_circuits=True in the cell below to use the pre-generated list.
[6]:
use_pregenerated_circuits = False
if use_pregenerated_circuits:
circuits_unfiltered = ae.io.load_test_circuits()
else:
kwargs = {
"iters": 36,
"complexity": 12,
"population_size": 100,
"generations": 30,
"terminals": "RLP",
"tol": 1e-2,
"parallel": True
}
circuits_unfiltered = ae.core.generate_equivalent_circuits(freq, Z, **kwargs)
# Since generating circuits is expensive, let's save the results to a CSV file
circuits_unfiltered.to_csv("circuits_unfiltered.csv", index=False)
# To load from file, uncomment the next 2 lines (line 2 is to convert str -> Python objects)
# circuits_unfiltered = pd.read_csv("circuits_unfiltered.csv")
# circuits_unfiltered["Parameters"] = circuits_unfiltered["Parameters"].apply(eval)
circuits_unfiltered
[18:59:19] WARNING Julia is installed, but needs to be resolved...
Updating registry at `~/.julia/registries/General.toml`
Cloning git-repo `https://github.com/ma-sadeghi/EquivalentCircuits.jl`
Updating git-repo `https://github.com/ma-sadeghi/EquivalentCircuits.jl`
Resolving package versions...
Updating `~/work/AutoEIS/AutoEIS/.venv/julia_env/Project.toml`
[da5bd070] + EquivalentCircuits v0.3.1 `https://github.com/ma-sadeghi/EquivalentCircuits.jl#master`
[6099a3de] + PythonCall v0.9.31
[458c3c95] + OpenSSL_jll v3.5.5+0
Updating `~/work/AutoEIS/AutoEIS/.venv/julia_env/Manifest.toml`
[47edcb42] + ADTypes v1.21.0
[79e6a3ab] + Adapt v4.5.0
[66dad0bd] + AliasTables v1.1.3
[4fba245c] + ArrayInterface v7.23.0
[a134a8b2] + BlackBoxOptim v0.6.4
[fa961155] + CEnum v0.5.0
[861a8166] + Combinatorics v1.1.0
[bbf7d656] + CommonSubexpressions v0.3.1
[34da2185] + Compat v4.18.1
[992eb4ea] + CondaPkg v0.2.34
[187b0558] + ConstructionBase v1.6.0
[9a962f9c] + DataAPI v1.16.0
⌅ [864edb3b] + DataStructures v0.18.22
[e2d170a0] + DataValueInterfaces v1.0.0
[8bb1440f] + DelimitedFiles v1.9.1
[163ba53b] + DiffResults v1.1.0
[b552c78f] + DiffRules v1.15.1
[a0c0ee7d] + DifferentiationInterface v0.7.16
[31c24e10] + Distributions v0.25.123
[ffbed154] + DocStringExtensions v0.9.5
[4e289a0a] + EnumX v1.0.7
[da5bd070] + EquivalentCircuits v0.3.1 `https://github.com/ma-sadeghi/EquivalentCircuits.jl#master`
[1a297f60] + FillArrays v1.16.0
[6a86dc24] + FiniteDiff v2.29.0
[f6369f11] + ForwardDiff v1.3.3
[6b9d7cbe] + GeneralizedGenerated v0.3.3
[0e44f5e4] + Hwloc v3.3.0
[34004b35] + HypergeometricFunctions v0.3.28
[92d709cd] + IrrationalConstants v0.2.6
[82899510] + IteratorInterfaceExtensions v1.0.0
[692b3bcd] + JLLWrappers v1.7.1
[682c06a0] + JSON v1.4.0
[b14d175d] + JuliaVariables v0.2.4
⌃ [d3d80556] + LineSearches v7.5.1
[2ab3a3ac] + LogExpFunctions v0.3.29
[d8e11817] + MLStyle v0.4.17
[1914dd2f] + MacroTools v0.5.16
[0b3b1443] + MicroMamba v0.1.15
[e1d29d7a] + Missings v1.2.0
⌅ [d41bc354] + NLSolversBase v7.10.0
[77ba4419] + NaNMath v1.1.3
[71a1bf82] + NameResolution v0.1.5
⌅ [429524aa] + Optim v1.13.3
[bac558e1] + OrderedCollections v1.8.1
[90014a1f] + PDMats v0.11.37
[69de0a69] + Parsers v2.8.3
[fa939f87] + Pidfile v1.3.0
[85a6dd25] + PositiveFactorizations v0.2.4
⌅ [aea7be01] + PrecompileTools v1.2.1
[21216c6a] + Preferences v1.5.2
[8162dcfd] + PrettyPrint v0.2.0
[43287f4e] + PtrArrays v1.4.0
[6099a3de] + PythonCall v0.9.31
[1fd47b50] + QuadGK v2.11.2
[189a3867] + Reexport v1.2.2
[ae029012] + Requires v1.3.1
[79098fc4] + Rmath v0.9.0
[6c6a2e73] + Scratch v1.3.0
[efcf1570] + Setfield v1.1.2
[a2af1166] + SortingAlgorithms v1.2.2
[d4ead438] + SpatialIndexing v0.1.6
[276daf66] + SpecialFunctions v2.7.1
[1e83bf80] + StaticArraysCore v1.4.4
[82ae8749] + StatsAPI v1.8.0
[2913bbd2] + StatsBase v0.34.10
[4c63d2b9] + StatsFuns v1.5.2
[ec057cc2] + StructUtils v2.7.1
[3783bdb8] + TableTraits v1.0.1
[bd369af6] + Tables v1.12.1
[e17b2a0c] + UnsafePointers v1.0.0
[e33a78d0] + Hwloc_jll v2.13.0+1
[94ce4f54] + Libiconv_jll v1.18.0+0
[458c3c95] + OpenSSL_jll v3.5.5+0
[efe28fd5] + OpenSpecFun_jll v0.5.6+0
[f50d1b31] + Rmath_jll v0.5.1+0
⌅ [02c8fc9c] + XML2_jll v2.13.9+0
[a65dc6b1] + Xorg_libpciaccess_jll v0.18.1+0
[f8abcde7] + micromamba_jll v2.3.1+0
[4d7b5844] + pixi_jll v0.41.3+0
[0dad84c5] + ArgTools v1.1.1
[56f22d72] + Artifacts
[2a0f44e3] + Base64
[ade2ca70] + Dates
[8ba89e20] + Distributed
[f43a241f] + Downloads v1.6.0
[7b1f6079] + FileWatching
[9fa8497b] + Future
[b77e0a4c] + InteractiveUtils
[4af54fe1] + LazyArtifacts
[b27032c2] + LibCURL v0.6.4
[76f85450] + LibGit2
[8f399da3] + Libdl
[37e2e46d] + LinearAlgebra
[56ddb016] + Logging
[d6f4376e] + Markdown
[a63ad114] + Mmap
[ca575930] + NetworkOptions v1.2.0
[44cfe95a] + Pkg v1.10.0
[de0858da] + Printf
[3fa0cd96] + REPL
[9a3f8284] + Random
[ea8e919c] + SHA v0.7.0
[9e88b42a] + Serialization
[6462fe0b] + Sockets
[2f01184e] + SparseArrays v1.10.0
[10745b16] + Statistics v1.10.0
[4607b0f0] + SuiteSparse
[fa267f1f] + TOML v1.0.3
[a4e569a6] + Tar v1.10.0
[8dfed614] + Test
[cf7118a7] + UUIDs
[4ec0a83e] + Unicode
[e66e0078] + CompilerSupportLibraries_jll v1.1.1+0
[deac9b47] + LibCURL_jll v8.4.0+0
[e37daf67] + LibGit2_jll v1.6.4+0
[29816b5a] + LibSSH2_jll v1.11.0+1
[c8ffd9c3] + MbedTLS_jll v2.28.1010+0
[14a3606d] + MozillaCACerts_jll v2025.12.2
[4536629a] + OpenBLAS_jll v0.3.23+5
[05823500] + OpenLibm_jll v0.8.5+0
[bea87d4a] + SuiteSparse_jll v7.2.1+1
[83775a58] + Zlib_jll v1.2.13+1
[8e850b90] + libblastrampoline_jll v5.11.0+0
[8e850ede] + nghttp2_jll v1.52.0+1
[3f19e933] + p7zip_jll v17.6.1+0
Info Packages marked with ⌃ and ⌅ have new versions available. Those with ⌃ may be upgradable, but those with ⌅ are restricted by compatibility constraints from upgrading. To see why use `status --outdated -m`
No Changes to `~/work/AutoEIS/AutoEIS/.venv/julia_env/Project.toml`
No Changes to `~/work/AutoEIS/AutoEIS/.venv/julia_env/Manifest.toml`
[6]:
| circuitstring | Parameters | |
|---|---|---|
| 0 | [R1,P2]-[L3,R4-P5] | {'R1': 4247753.476875023, 'P2w': 2.11254418350... |
| 1 | R1-[R2,P3] | {'R1': 168.52800909953987, 'R2': 4614180.28355... |
| 2 | L1-[R2,P3]-R4 | {'L1': 1.2929170013574218e-08, 'R2': 4629894.6... |
| 3 | [R1-P2-L3,R4] | {'R1': 139.1650445028641, 'P2w': 1.98649988210... |
| 4 | [L1-[L2,R3]-[P4,R5]-R6-L7,R8] | {'L1': 5.263421013978851e-08, 'L2': 1.57362595... |
| 5 | R1-[R2,P3] | {'R1': 169.056620252914, 'R2': 4590000.5032784... |
| 6 | P1-[R2,P3]-[P4,R5] | {'P1w': 33010920.933207385, 'P1n': 1.0, 'R2': ... |
| 7 | [R1-[R2,P3],R4] | {'R1': 0.007188355748693638, 'R2': 18312812.67... |
Filter candidate equivalent circuits¶
Note that all these circuits generated by the GEP process probably fit the data well, but they may not be physically meaningful. Therefore, we need to filter them to find the ones that are most plausible. AutoEIS uses “statistical plausibility” as a proxy for gauging “physical plausibility”. To this end, AutoEIS provides a function to filter the candidate circuits based on some heuristics (read our paper for the exact steps and the supporting rationale).
[7]:
circuits = ae.core.filter_implausible_circuits(circuits_unfiltered)
# Let's save the filtered circuits to a CSV file as well
circuits.to_csv("circuits_filtered.csv", index=False)
# To load from file, uncomment the next 2 lines (line 2 is to convert str -> Python objects)
# circuits = pd.read_csv("circuits_filtered.csv")
# circuits["Parameters"] = circuits["Parameters"].apply(eval)
circuits
[7]:
| circuitstring | Parameters | |
|---|---|---|
| 0 | R1-[R2,P3] | {'R1': 168.52800909953987, 'R2': 4614180.28355... |
| 1 | L1-[R2,P3]-R4 | {'L1': 1.2929170013574218e-08, 'R2': 4629894.6... |
Perform Bayesian inference¶
Now that we have narrowed down the candidate circuits to a few good ones, we can perform Bayesian inference to find the ones that are statistically most plausible.
[8]:
results = ae.core.perform_bayesian_inference(circuits, freq, Z)
Visualize results¶
Now, let’s take a look at the results. perform_bayesian_inference returns a list of InferenceResult objects. Each InferenceResult object contains all the information about the Bayesian inference, including the posterior distribution, the prior distribution, the likelihood function, the trace, and the summary statistics.
Before we visualize the results, let’s take a look at the summary statistics. The summary statistics are the mean, the standard deviation, and the 95% credible interval of the posterior distribution. The summary statistics are useful for quickly gauging the uncertainty of the parameters.
[9]:
for result in results:
if result.converged:
ae.visualization.print_summary_statistics(result.mcmc, result.circuit)
R1-[R2,P3], 0/1000 divergences ┏━━━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┓ ┃ Parameter ┃ Mean ┃ Std ┃ Median ┃ 5.0% ┃ 95.0% ┃ ┡━━━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━┩ │ P3n │ 9.39e-01 │ 3.36e-03 │ 9.39e-01 │ 9.34e-01 │ 9.44e-01 │ │ P3w │ 1.97e-06 │ 3.20e-08 │ 1.97e-06 │ 1.92e-06 │ 2.02e-06 │ │ R1 │ 1.39e+02 │ 2.83e+00 │ 1.39e+02 │ 1.35e+02 │ 1.44e+02 │ │ R2 │ 4.59e+06 │ 1.09e+05 │ 4.60e+06 │ 4.41e+06 │ 4.76e+06 │ │ sigma.mag │ 2.82e-02 │ 2.73e-03 │ 2.79e-02 │ 2.40e-02 │ 3.28e-02 │ │ sigma.phase │ 9.84e-02 │ 9.65e-03 │ 9.76e-02 │ 8.44e-02 │ 1.15e-01 │ └─────────────┴──────────┴──────────┴──────────┴──────────┴──────────┘
L1-[R2,P3]-R4, 0/1000 divergences ┏━━━━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━┓ ┃ Parameter ┃ Mean ┃ Std ┃ Median ┃ 5.0% ┃ 95.0% ┃ ┡━━━━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━┩ │ L1 │ 5.07e-12 │ 1.15e-10 │ 5.36e-16 │ 3.32e-19 │ 1.00e-12 │ │ P3n │ 9.39e-01 │ 3.33e-03 │ 9.39e-01 │ 9.34e-01 │ 9.44e-01 │ │ P3w │ 1.97e-06 │ 3.06e-08 │ 1.97e-06 │ 1.92e-06 │ 2.02e-06 │ │ R2 │ 4.59e+06 │ 1.08e+05 │ 4.59e+06 │ 4.42e+06 │ 4.77e+06 │ │ R4 │ 1.39e+02 │ 2.72e+00 │ 1.39e+02 │ 1.35e+02 │ 1.44e+02 │ │ sigma.mag │ 2.81e-02 │ 2.76e-03 │ 2.79e-02 │ 2.40e-02 │ 3.31e-02 │ │ sigma.phase │ 9.77e-02 │ 9.65e-03 │ 9.70e-02 │ 8.27e-02 │ 1.15e-01 │ └─────────────┴──────────┴──────────┴──────────┴──────────┴──────────┘
Note that some rows have been highlighted in yellow, indicating that the standard deviation is greater than the mean. This is not necessarily a bad thing, but it screams “caution” due to the high uncertainty. In this case, we need to check the data and the model to see if there is anything wrong. For example, the data may contain outliers, or the model may be overparameterized.
Before we investigate the posteriors for individual circuit components for each circuit, let’s take a bird’s eye view of the results, so you have a general feeling about which circuits are generally better, and which ones are worse. For this purpose, we first need to evaluate the circuits based on some common metrics, and then rank them accordingly:
[10]:
# We first need to augment the circuits dataframe with MCMC results
circuits["InferenceResult"] = results
# Now, we can compute the fitness metrics, then rank/visualize accordingly
circuits = ae.core.compute_fitness_metrics(circuits, freq, Z)
ae.visualization.print_inference_results(circuits)
[10]:
Inference results ┏━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━┓ ┃ Circuit ┃ WAIC (mag) ┃ WAIC (phase) ┃ R2 (re) ┃ R2 (im) ┃ MAPE (re) ┃ MAPE (im) ┃ Np ┃ ┡━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━┩ │ L1-[R2,P3]-R4 │ -3.21e+02 │ -9.75e+01 │ 0.981 │ 0.609 │ 3.43e+01 │ 2.03e+01 │ 5 │ │ R1-[R2,P3] │ -3.20e+02 │ -9.83e+01 │ 0.981 │ 0.608 │ 3.45e+01 │ 2.04e+01 │ 4 │ └───────────────┴────────────┴──────────────┴─────────┴─────────┴───────────┴───────────┴────┘
Now, let’s take one step further and visualize the results. To get an overview of the results, we can plot the posterior distributions of the parameters as well as the trace plots. It’s an oversimplification, but basically, a good posterior distribution should be unimodal and symmetric, and the trace plot should be stationary. In probabilistic terms, this means that given the circuit model, the data are informative about the parameters, and the MCMC algorithm has converged.
On the other hand, if the posterior distribution is multimodal or skewed, or the trace plot is not stationary, it means that the data are not informative about the parameters, and the MCMC algorithm has not converged. In this case, we need to check the data and the model to see if there is anything wrong. For example, the data may contain outliers, or the model may be overparameterized.
Note
For the following cell to work, you need to set interactive=True at the beginning of the notebook. It’s turned off by default since GitHub doesn’t render interactive plots.
[11]:
def plot_trace(samples):
"""Plots the posterior and trace of a variable in the MCMC sampler."""
output = widgets.Output()
with output:
fig, ax = plt.subplots(ncols=2, figsize=(9, 3))
log_scale = bool(np.std(samples) / np.median(samples) > 2)
kwargs_hist = {
"stat": "density",
"log_scale": log_scale,
"color": "lightblue",
"bins": 25,
}
# ax[0] -> posterior, ax[1] -> trace
sns.histplot(samples, **kwargs_hist, ax=ax[0])
kwargs_kde = {"log_scale": log_scale, "color": "red"}
sns.kdeplot(samples, **kwargs_kde, ax=ax[0])
# Plot trace
ax[1].plot(samples, alpha=0.5)
ax[1].set_yscale("log" if log_scale else "linear")
plt.show(fig)
return output
def plot_trace_all(mcmc: "numpyro.MCMC", circuit: str):
"""Plots the posterior and trace of all variables in the MCMC sampler."""
variables = ae.parser.get_parameter_labels(circuit)
samples = mcmc.get_samples()
children = [plot_trace(samples[var]) for var in variables]
tab = widgets.Tab()
tab.children = children
tab.titles = variables
return tab
def dropdown_trace_plots():
"""Creates a dropdown menu to select a circuit and plot its trace."""
def on_dropdown_clicked(change):
with output:
output.clear_output()
idx = circuits_list.index(change.new)
plot = trace_plots[idx]
display(plot)
dropdown = widgets.Dropdown(
description="Circuit:", options=circuits_list, value=circuits_list[0]
)
output = widgets.Output(layout={"width": "850px"})
dropdown.observe(on_dropdown_clicked, names="value")
display(dropdown, output)
# Default to the first circuit
with output:
display(trace_plots[0])
# Cache rendered plots to avoid re-rendering
circuits_list = circuits["circuitstring"].tolist()
trace_plots = []
for i, row in circuits.iterrows():
circuit = row["circuitstring"]
mcmc = row["InferenceResult"].mcmc
if row["converged"]:
trace_plots.append(plot_trace_all(mcmc, circuit))
else:
trace_plots.append("Inference failed")
if interactive:
dropdown_trace_plots()
The functions defined in the above cell are used to make the interactive dropdown menu. The dropdown menu lets you select a circuit model, and shows the posterior distributions of the parameters as well as the trace plots. The dropdown menu is useful for quickly comparing the results of different circuit models. Running this cell for the first time may take a while (~ 5 seconds per circuit), but once run, all the plots will be cached.
The distributions for the most part look okay, although in some cases (like R2 and R4 in the first circuit) the span is quite large (~ few orders of magnitude). Nevertheless, the distributions are bell-shaped. The trace plots also look stationary.
Now, let’s take a look at the posterior predictive distributions. “Posterior predictive” is a fancy term for “model prediction”, meaning that after we have performed Bayesian inference, we can use the posterior distribution to make predictions. In this case, we can use the posterior distribution to predict the impedance spectrum and compare it with our measurements and see how well they match. After all, all the posteriors might look good (bell-shaped, no multimodality, etc.) but if the model predictions don’t match the data, then the model is not good.
Note
For the following cell to work, you need to set interactive=True at the beginning of the notebook. It’s turned off by default since GitHub doesn’t render interactive plots.
[12]:
def plot_nyquist(mcmc: "numpyro.MCMC", circuit: str):
"""Plots Nyquist plot of the circuit using the median of the posteriors."""
# Compute circuit impedance using median of posteriors
samples = mcmc.get_samples()
variables = ae.parser.get_parameter_labels(circuit)
percentiles = [10, 50, 90]
params_list = [[np.percentile(samples[v], p) for v in variables] for p in percentiles]
circuit_fn = ae.utils.generate_circuit_fn(circuit)
Zsim_list = [circuit_fn(freq, params) for params in params_list]
# Plot Nyquist plot
fig, ax = plt.subplots(figsize=(5.5, 4))
for p, Zsim in zip(percentiles, Zsim_list):
ae.visualization.plot_nyquist(Zsim, fmt="-", label=f"model ({p}%)", ax=ax)
ae.visualization.plot_nyquist(Z, fmt=".", label="measured", ax=ax)
# Next line is necessary to avoid plotting the first time
plt.close(fig)
return fig
def dropdown_nyquist_plots():
"""Creates a dropdown menu to select a circuit and plot its Nyquist plot."""
def on_change(change):
with output:
output.clear_output()
idx = circuits_list.index(change.new)
fig = nyquist_plots[idx]
display(fig)
output = widgets.Output(layout={"width": "550px"})
dropdown = widgets.Dropdown(
options=circuits_list, value=circuits_list[0], description="Circuit:"
)
dropdown.observe(on_change, names="value")
display(dropdown, output)
# Default to the first circuit
with output:
display(nyquist_plots[0])
# Cache rendered plots to avoid re-rendering
circuits_list = circuits["circuitstring"].tolist()
nyquist_plots = []
for i, row in circuits.iterrows():
circuit = row["circuitstring"]
mcmc = row["InferenceResult"].mcmc
if row["converged"]:
nyquist_plots.append(plot_nyquist(mcmc, circuit))
else:
nyquist_plots.append("Inference failed")
if interactive:
dropdown_nyquist_plots()